Cách tách dấu thanh và chữ cái có dấu trong tiếng Việt thành chữ Latin với Elixir
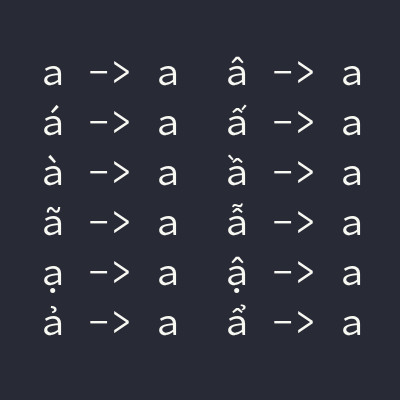
Xin chào, ở bài viết này, trước tiên tôi muốn nói đến vấn đề của mình, Khi phát triển phần mềm Mining Rig Monitor, tôi muốn sử dụng các tên tiếng Việt để đặt tên cho dàn đào. Ví dụ:
- Thanh Long
- Bạch Hổ
- Huyền Vũ
- Chu Tước
Khi gài vào phần mềm khai thác tiền mã hóa, tôi muốn những cái tên này như sau, dấu gạch ngang tôi sẽ đề cập sau:
- Thanh-Long (giữ nguyên)
- Bach-Ho (mất dấu nặng dưới chữ
a, mũ và dấu hỏi của chữổ) - Huyen-Vu (chữ
ềthành chữe, chữũthành chữu) - Chu-Tuoc (
ướcthànhuoc)
Giải pháp như sau, với function remove_diacritical_marks/1:
def remove_diacritical_marks(string) when is_binary(string) do
# á à ã ạ ả: dấu sắc, huyền, ngã, nặng, hỏi
list_1 = [769, 768, 771, 803, 777]
# â, ă, ư
list_2 = [770, 774, 795]
string
|> String.normalize(:nfd)
|> String.to_charlist()
|> Enum.filter(fn(e) ->
Enum.member?(list_1 ++ list_2, e) == false
end)
|> Kernel.to_string()
end
Còn đây là test case:
defmodule MiningRigMonitor.UtilityTest do
use ExUnit.Case
alias MiningRigMonitor.Utility
test "remove_diacritical_marks 1" do
string = """
a á à ã ạ ả
â ấ ầ ẫ ậ ẩ
ă ắ ằ ẳ ặ ẳ
e é è ẽ ẹ ẻ
ê ế ề ễ ệ ể
u ú ù ũ ụ ủ
ư ứ ừ ữ ự ử
o ó ò õ ọ ỏ
ơ ớ ờ ỡ ợ ở
"""
test_result = Utility.remove_diacritical_marks(string)
expected_result = """
a a a a a a
a a a a a a
a a a a a a
e e e e e e
e e e e e e
u u u u u u
u u u u u u
o o o o o o
o o o o o o
"""
assert(test_result == expected_result)
end
test "remove_diacritical_marks 2" do
string = """
A Á À Ã Ạ Ả
 Ấ Ầ Ẫ Ậ Ẩ
Ă Ắ Ằ Ẳ Ặ Ẳ
E É È Ẽ Ẹ Ẻ
Ê Ế Ề Ễ Ệ Ể
U Ú Ù Ũ Ụ Ủ
Ư Ứ Ừ Ữ Ự Ử
O Ó Ò Õ Ọ Ỏ
Ơ Ớ Ờ Ỡ Ợ Ở
"""
test_result = Utility.remove_diacritical_marks(string)
expected_result = """
A A A A A A
A A A A A A
A A A A A A
E E E E E E
E E E E E E
U U U U U U
U U U U U U
O O O O O O
O O O O O O
"""
assert(test_result == expected_result)
end
end
Phương pháp của tôi là tách chữ có dấu thành một danh sách chữ + dấu liên quan. (Trong Elixir, module String, nó gọi là Normalization Form Canonical Decomposition - nfd). Nguyên văn tiếng anh như sau:
:nfd - Normalization Form Canonical Decomposition. Characters are decomposed by canonical equivalence,
and multiple combining characters are arranged in a specific order.
Ví dụ:
- chứ
álàa + dấu sắc. - chữ
ấlàa + mũ + dấu sắc.
iex(3)> String.normalize("á", :nfd) |> String.to_charlist
[97, 769]
iex(4)> String.normalize("ấ", :nfd) |> String.to_charlist
[97, 770, 769]
Dưới đây là danh sách thanh sắc, ký hiệu mà tôi mò được.
# á à ã ạ ả: dấu sắc, huyền, ngã, nặng, hỏi
list_1 = [769, 768, 771, 803, 777]
# â, ă, ư
list_2 = [770, 774, 795]
Bạn thấy đấy, sau khi có danh sách này, việc cần làm chỉ là dùng Enum.filter/2, nếu mà char nào nằm trong nhóm list_1 & list_2 thì chúng ta loại bỏ.
Kết quả lúc này là 1 charlist []. Để biến nó thành String, tôi dùng String.to_string/1.
Còn về cái dấu gạch ngang -. Tôi sử dụng regular expression |> String.replace(~r([^a-zA-Z0-9]),"-") sau khi đã chạy qua remove_diacritical_marks/1.
Hi vọng tôi đã có thể giúp tiết kiệm 2 phút cuộc đời với cái này!
Reference:
- Elixir, String.normalize/1, https://hexdocs.pm/elixir/String.html#normalize/2